Indexing Enormous Sites - Hints and Tips
File and Folder structureStore sample data in a organized manner
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

| Spider Mode | Offline mode |
| Fast stable network connection | Fast internal hard disks. Preferably 2 or more. Read speed is more critical that write. |
| Lots of RAM (at least 2GB + 1GB per 1 million files indexed) | Fast CPU Dual or quad core preferred. But more than 4 cores doesn't add much benefit. |
| Fast CPU Dual or quad core preferred. But more than 4 cores doesn't add much benefit | Lots of RAM. (at least 2GB + 512MB per 1 million files indexed) |
| Disk is not so critical | Network connection is not critical |
It should be noted that Zoom will not proceed with indexing if it estimates that you need over 135% of the Total amount of RAM (note that this is not just available RAM, but the total RAM you have installed) on your computer. If you get this type of warning you will either need to install more RAM or run the indexing from a different machine with a greater amount of RAM.
Index one site at a time when using an unreliable connection
When trying to index a number of sites over an unreliable connection, it is safer to index one domain at a time using Zoom's incremental indexing tool ("Index"->"Incremental indexing "->"Add start points or domains to existing index"), making sure to backup the index files after the successful indexing of each domain.
Configuring Zoom
Use the CGI option in Zoom
If your dataset is considerably large and consists of over 65,000 files, you will need to set the platform to CGI in Zoom. The CGI version can support sites containing a million pages or more (depending on the content). The more RAM the indexing machine has, the greater the number of files supported.
The CGI version also provides high-performance support for very large sites. It is a binary application so it does not have any of the overhead issues of scripting languages such as PHP or ASP.
Use multiple threads
When using the spidering mode to index large sites, you should set the field "Multiple threads" (under "Configure"->"Spider options") to at least 2. This option tells Zoom to use multiple dedicated threads for downloading files, which will greatly increase the speed of the indexing. This option essentially allows Zoom to download multiple files in the background whilst indexing at the same time. The optimal setting depends on network bandwidth and latency, the speed of the site being indexed, and how much load you want to put on the site being indexed. Note that if you are indexing a site you don't own, then it is considered polite not to load the server too heavily (you can use "Spider throttling" to ensure this).
Index more pages and less words
The field "Max unique words" has a considerable impact on the amount of RAM required by the Zoom Indexer. On a typical 32-bit machine with 2GB of RAM you will be limited to setting this field to around 7 million unique words, when indexing around 5 million files. In order to index a greater number of files before hitting the max unique words limit, you could use the "Limit words per file" field. This option essentially restricts the indexer from indexing more than the set number of words per file, meaning that any unique words further down in the file will not be indexed, and hence increasing the number of files that you could potentially index. The most interesting sections of a document are generally near the top of the document. So limiting the words indexed per file can often reduce the RAM usage without having a significant negative impact on the search accuracy.
Index multiple pages from 1 domain
When using Spidering Index mode, it is considerably faster to index ten pages from one single site than to index one page from ten different sites. This is because when indexing from one single site the Indexer only needs to create a single http protocol session instead of one for each of the ten sites. Also, the multi threading feature in Spider mode works a lot better with just one site compared against multiple sites.
Use conservative limits when using spider mode on 32-bit
When using Spider mode on a 32-bit machine, it is recommended that the "Estimated RAM required" on the Limits tab is no more than two thirds of your total RAM. This is because Spidering consumes a considerable amount more memory than offline mode, and on 32-bit windows the amount of virtual memory is limited to 2GB. For example, on a 32-bit Windows Vista machine with 2GB RAM, max files to index set to 1 million, max unique words set to 2 million, and estimated RAM required set to 1.9GB, virtual memory peaked out after about 5 hours causing the Indexer to stop. If this happens, users should still be able to add additional pages to the set of index files, by restarting the machine and using the incrementally indexing options.
Index in offline mode when possible
Depending on the site, indexing in Offline mode consumes around 50% less RAM than indexing in Spider mode, and can be almost 3 times faster. Therefore if you are trying to index an extremely large website or group of websites, and you have access to the web pages themselves, it might be worth considering creating the indexes in offline mode especially if the network is slow or unreliable. It can change a 3 day indexing job to a 1 day job.
Experiment with optimization bar
If you are unhappy with the performance of the CGI i.e. you would rather give preference to either faster searches - at the cost of accuracy and potentially omitting some search results, or more accurate search results - at the expense of slower searching, then you can experiment with the Optimization slider bar. This bar allows you to configure 3 different settings: Max matches, Max content seeks, and Max search time. The Optimization bar is especially important with exact phrase matching, and searches which may return a huge number of results (e.g. over 1000). It is also important when indexing very large sites or datasets which contain over 1 million files. The bar should hopefully allow you to obtain the right balance between search accuracy and search speed.
Ensure configuration file is correct. Start small and ramp up
When indexing large volumes of data it is highly recommended to ensure that your configuration is correct with a much smaller set of files first, before attempting to index the complete set. Taking this step will help to avoid wasting a number of days indexing the entire set of data, only to find out afterwards that your results are not being displayed the way that you want, or your indexes include a lot of pages and content that you don't want to be searchable, etc.
Also, ensuring that your configuration file is correct before indexing your complete dataset will help to avoid any problems when performing an incremental index. In order to perform an incremental index, you must NOT have modified your indexing configuration since the last index was made. The .ZCFG file must contain the exact same settings, and the index files must still be in the output folder specified. This means that if you index your entire website using a particular configuration file, and you decide later that you want to add some more additional web pages, then you must use the same configuration file as used earlier. If you try to make any config changes for the new web pages that were not in the original configuration file, then the incremental index will fail, and you'll be forced to do a full index instead.
File Filtering and Skipping
Filter out unwanted data
When indexing very large amounts of data, it can be highly advantageous to configure the "Skip options" and "Filtering" options in the Zoom configuration file. As can often be the case with large volume of data, there can be huge amounts of pages/data that you are not interested in, and would not like to include in your set of indexing files. Using the configure tab in Zoom Indexer and under the appropriate views, you have the option to skip these unwanted pages/data.
Use the Skip option
With the Skip option the user has the ability to skip pages and folders based on their filename/folder name. The user needs to add an entry in the "Page and folder skip list" for every type of file/folder that the user wants to skip (note this field is case sensitive). Use the skip list where possible, as it is more efficient than the filtering option. See the User's Guide for additional details.
Use the Filter option
Under the Filtering view options, users have the ability to skip pages based on their content rather than their filename. Users can skip pages depending on whether that page has or has not a particular word. To use this option the user, must check the "Enable content filtering" checkbox and specify a keyword proceeded with the appropriate rule ("+" implies that a page must include the keyword, "-" implies the page must not include the keyword). See the User's Guide for additional details.
Managing an Existing Index
Use incremental indexing to add new pages to large indexes
Zoom allows you to perform incremental indexing so that you can update, add pages, and make changes to an existing set of index files without having to perform a full re-index. This can be particularly useful for large sites (or an index of a large number of sites) where there may be minor incremental changes that require updates to the index, but would be too time consuming (or bandwidth consuming) to re-index the entire site using Spider mode on a regular basis. The option "Update an existing index" is only available in Spider Mode and not available in Offline Mode. Offline mode indexing does not use any Internet traffic and hence is many times faster than spider mode, so this should not be necessary and we would recommend a full re-index for offline mode users. See the User's Guide for additional details about incremental indexing.
Add pages in batches
When adding pages to an existing large set of index files it is considerably more efficient to add a group of pages together rather than adding the pages one at a time. For example, with a set of index files consisting of 2.5 million pages it took the indexer 6:14 minutes to add a single page. On the other hand, adding a group of 5 pages only took 6:43 minutes (average 1.3 minutes per file). This is because the most time is spent loading the dictionary and data files into memory, and not adding the new files. With very large index files the amount of time taken to actually add a new page is insignificant compared with the initially indexing of these files.
Indexing Limitations
Although Zoom is capable of indexing a huge number of pages, it is worth noting that the 64bit software has some theoretical limitations. These are as follows:
| Maximum Base Unique Words (a base word is the stemmed word, e.g. "run") |
16 Million (16,777,216) |
| Maximum Variant Unique Words (a variant word is the un-stemmed word, e.g "running", "runs", "RUN", etc) |
256 Variant words per base word |
| Maximum Total Variant Unique Words | 4 Billion (16 Million X 256 = 4,294,967,296) |
| Maximum Number of Pages | 2 Billion (2,147,483,647) |
| Maximum number of words (non unique) | No fixed limit |
In the real word however, practical limits of available RAM, indexing time, machine stability and acceptable search times mean that the theoretical limits will probably not be hit.
In our real life testing a typical 32-bit Windows Vista machine with 2 GB of RAM, Zoom Indexer can support up to around 7 million unique words and 5 million indexed files in offline mode with the "Limit words per file" option set to 250 words.
On a 64-bit Windows machine with 4 GB of RAM, Zoom can support about 4 million files and 19 million unique words with no limit set on the number of words per page.
At this point the machines were running out of RAM, indexing times where measured in days, and some of the worst case search times were getting to be unacceptably long. So in general we would suggest staying well below these limits until hardware and network performance improves in future years. See the example below.
Real Life Example (indexing Wikipedia)
The following test scenario was carried out in order to demonstrate Zoom's capabilities in indexing vast volumes of data, and to uncover any limitations that it may have.Sample Data
For our tests we used a set of static HTML dumps of Wikipedia (http://static.wikipedia.org/) from the English June 2008 edition. The total number of folders was 85,651 and files 14,257,513 with a total uncompressed file size of 325GB (on disk), of which the photos and images accounted for 93GB. The folder structure was .../<letter>/<letter>/<letter>/ and then a collection of the appropriate html pages for that particular directory. For example if you were looking for a page on Zombies, you would navigate to .../z/o/m/ and look for the zombies.html page.
Hardware Configuration
2 different machines were used to test the relative limitations of indexing large volumes of data. They were:
Windows 32-bit Machine:
Gigabyte GA-MA790XT-UD4P Motherboard
2.6 GHz AMD Phenom II X4 910 (4 cores)
2 GB DDR3 RAM
750GB Barracuda SATA hard drive (7200rpm and 32MB cache) for the output of index files
500GB Barracuda SATA hard drive (7200rpm and 32MB cache) to store sample wikipedia data
Windows Vista Ultimate 32-bit
Windows 64-bit Machine:
Intel DX58S0 Motherboard
2.67Ghz Intel Core i7 920 (4 cores + hyperthreading)
4GB DDR3 RAM
500GB Western Digital SATA hard drive (7200rpm and 16MB cache) for the output of index files
500GB Hitachi SATA hard drive (7200rpm and 16MB cache) to store Wikipedia sample data
Windows 7 Ultimate 64-bit
A 32-bit version of Zoom Indexer in offline mode was run on the 32-bit machine . The sample data was directly access via the filesystem in offline mode. On the 64-bit machine, the 64-bit version of Zoom was run in Offline mode and Spider mode. For Spider mode the target site was hosted locally on the machine via an Apache HTTP Server.
Zoom configuration file:
V6 build 1014 of Zoom was used.
| Configuration Options | 32-bit |
64-bit |
64-bit (Spider) |
| Indexing mode | Offline mode |
Spider mode |
|
| Platform | CGI/Win32 |
||
| Multiple threads | NA |
10 |
|
| Max limit for files to index | 5,000,000 |
10,000,000 |
5,000,000 |
| Max limit for unique words | 7,250,000 |
19,500,000 |
14,000,000 |
| Limit words per file | 150 |
None |
250 |
| Optimization slider | Max matches = 10000, Max context seeks = 5000, Max search time = 120 seconds |
||
| Content Filtering | -Redirecting, -Orbital period |
||
| Page and folder skip list | Talk, talk, sandbox |
||
In our real-life scenario we had a large number of Wikipedia "Talk" pages separate from the main content which we were generally not interested in. In order to configure the Indexer to skip any of these types of pages or folders we added the words "Talk" and "talk" (Both cases were needed due to case sensitivity) to the "Page and folder skip list" in the Skip options view.
With this configuration change the Indexer checks each file and folder name for any of the words in the skip list and will then skip appropriately.
Likewise we had a large number of redirect pages which had very little content on them except for a redirect link. In order for us to skip these types of pages based on their content, we simple added "-Redirecting" to the filtering list.
The main reason why we added these configurations options to skip these types of pages was that our set of sample data was extremely large (over 14 million files) and we only wanted to index the more relevant and interesting set of pages.
Screenshot of 64-bit machine in spider mode:
This screen shot shows 3.7million pages and 891 million words indexed during a period of 3.8 days of continuous indexing.
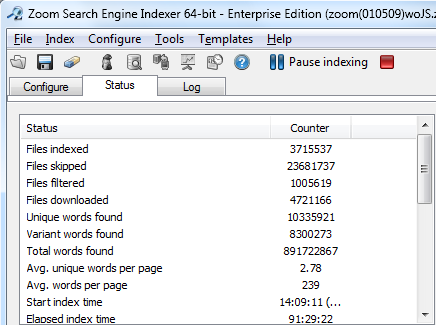
Final metric results:
| METRIC | MACHINE 1 (32BIT) |
MACHINE 2 (64BIT SPIDER MODE) |
MACHINE 2 (64BIT, OFFLINE MODE) |
| Files indexed | 2,752,682 |
3,715,537 |
4,450,797 |
| Files skipped | 5,562,179 |
23,681,737 |
7,741,278 |
| Files filtered | 1,514,815 |
1,005,619 |
2,488,281 |
| Files downloaded | N/A |
4,721,166 |
N/A |
| Unique words found | 7,250,000 |
10,335,921 |
19,500,000 |
| Variant words found | 5,889,984 |
8,300,273 |
14,869,970 |
| Total words found | 432,244,142 |
891,722,867 |
2,515,481,986 |
| Avg. Unique words per page | 2.63 |
2.78 |
4.38 |
| Avg. Words per page | 157 |
239 |
565 |
| Elapsed index time | 23:42 (HH:MM) |
91:29 (HH:MM) |
73:34 (HH:MM) |
| Peak physical memory used during indexing (MB) | 789 |
2,717 |
2,555 |
| Peak virtual memory used during indexing (MB) | 1,712 |
6,386 |
4,749 |
| Size of index files (GB) | 4.85 |
10 |
22.9 |
| Size of index as a % of source data | 4% |
7% |
10% |
| Typical single word search times (Core i7 CPU, 64bit, 4GB Ram) |
6 SECS |
7 SECS |
11 SECS |
| Typical exact phrase search times (Core i7 CPU, 64bit, 4GB Ram) |
5 TO 7 SECS |
10 TO 30 SECS |
15 TO 50 SECS |
Dedicated search Appliances
Further significant performance improvements can be made by switching to a dedicated search appliance. We offer bespoke search appliances as a service. By using a dedicated machine it is possible to switch from using the CGI option to a related technology known as FastCGI. Example peformance improvements are as follows.
| Search Type | CGI Search times | FastCGI Search Times |
| Single Word | 4.4 sec |
0.05 sec |
| Multi-word | 4.4 sec |
0.08 sec |
| Wildcard search | 4.6 sec |
0.09 sec |
| Exact phrase | 5.6 sec |
0.44 sec |
Times measured on a old P4 hardware with a million page index.
Advantages of FASTCGI
- Massive increases in search speed as a result of advanced caching and the removal of disk access.
Disadvantages of FASTCGI
- Significantly more RAM is required in the server, and the RAM is held in use over a longer period of time.
- Initial setup is more complex than CGI (which can already be complex on some servers)
- Slightly more ongoing maintanence is required.
- The update of the index can be more complex
So the implementation of FASTCGI only really makes sense on dedicated servers. If you are interested, contact us for more information about FASTCGI and dedicated appliances.
- Back to our FAQ page